isladogs
Access MVP / VIP
- Local time
- Today, 10:51
- Joined
- Jan 14, 2017
- Messages
- 19,549
This is a follow up to a recent thread Desperate-Count Help Needed https://www.access-programmers.co.uk/forums/showpost.php?p=1597549&postcount=8
Part of this included discussion of the comparative efficiency of aggregate queries using WHERE with HAVING.
I thought that Galaxiom explained this very clearly so I've quoted him below:
I agreed completely with what was written by Galaxiom in that post.
I decided to adapt my speed comparison test utility to demonstrate this point for future use.
Unfortunately, the results were nothing like as clear cut as I had expected so I did two different versions with different datasets
a) Postcodes
For this test, I used my large Postcodes table with 2.6 million records.
Unfortunately, I cannot upload the database used as the large dataset means it is 240 MB in size
The number of postcodes for selected areas, districts, sectors & zones were counted and the results appended to a data table. There are around 700 aggregated records created
This was done in 2 ways:
1. HAVING - data is grouped then filtered, counted & added to the data table one at a time
2. WHERE - data is filtered then grouped, counted & added one at a time
The tests were each run 10 times and the average calculated for each test

Unexpectedly using HAVING was slightly faster but the difference in times was negligible
b) Patients
I then decided to try again adapting the dataset from my recent patient login kiosk mode example.
I imported the same 3300 records 9 times over to give a dataset of around 30000 records.
Duplicating patient names and dates of birth doesn’t matter for these tests.
Each record includes gender & date of birth (both indexed).
The database for this test is small enough to upload (attached)
Code was used to count the number of records grouping by birth day & birth month as well as gender and appended these record counts to another table.
The tests each created just over 700 records on each run.
As there were fewer records in this dataset, the code looped through each 3 times in each test
All tests were repeated 5 times and average values calculated
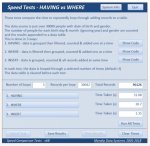
This time, there were 3 different tests:
1. HAVING - data is first grouped then filtered, counted and appended one at a time
2. WHERE – data is first filtered then grouped, counted and appended one at a time
3. INSERT – data is grouped then all records were appended ‘at once’
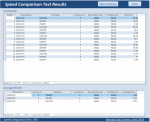
Results were as follows
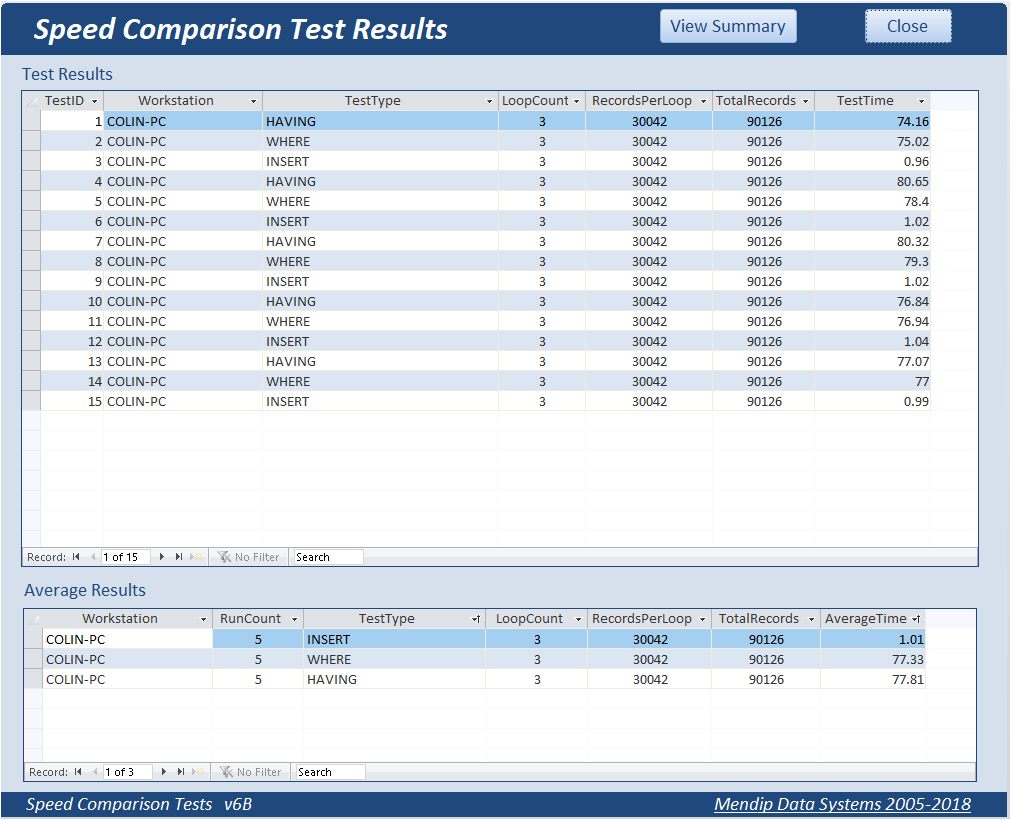
In these tests WHERE was faster than HAVING but the difference between them was once again negligible.
INSERT is of course dramatically faster than either of the other 2 methods as it all happens ‘at once’ rather than 'row by agonising row' (RBAR) in a recordset loop
=======================================================
Incidentally, I ran 4 different versions of the HAVING tests to compare the relative efficiency of each
All gave EXACTLY the same results but the times were VERY different
The comparative speeds were this time what I had expected
Method 1 (as above) - using Month & Day functions - approx. 78s for 3 loops
Method 2 - as method 1 but also formatting dates by mm/dd/yyyy - approx. 298s for 3 loops
Method 3 - using Left & Mid functions - approx. 170s for 3 loops
Method 4 – using Date Part functions – approx. 160s for 3 loops
========================================================
Overall Conclusions
The HAVING vs WHERE tests were done to provide evidence that the use of HAVING is far less efficient than using WHERE.
Logically this MUST be the case
However, the tests haven’t worked out anything like I had expected.
Now it may be that my code is flawed or my datasets not sufficiently large to make the relative efficiency of each test create significant differences.
:banghead:
OR I've just managed to show that this commonly expressed viewpoint is actually not true or has minimal effect.
I would appreciate others running the same tests and providing feedback on the results obtained.
I would also appreciate comments on the tests themselves together with any suggested improvements or alterations to the process.
Part of this included discussion of the comparative efficiency of aggregate queries using WHERE with HAVING.
I thought that Galaxiom explained this very clearly so I've quoted him below:
Code:
SELECT field1, Sum(field2)
FROM table
GROUP BY field1
HAVING field 1 = something
Code:
SELECT field1, Sum(field2)
FROM table
WHERE field 1 = something
GROUP BY field1
The first one is what the Access query designer encourages a novice to build. The second is what the query should be.
The difference is that the WHERE is applied before the GROUP BY while the HAVING is applied after. The first query will group all the records then only return the Having. The second query selects only the "something" records and the Group becomes trivial.
I agreed completely with what was written by Galaxiom in that post.
I decided to adapt my speed comparison test utility to demonstrate this point for future use.
Unfortunately, the results were nothing like as clear cut as I had expected so I did two different versions with different datasets
a) Postcodes
For this test, I used my large Postcodes table with 2.6 million records.
Unfortunately, I cannot upload the database used as the large dataset means it is 240 MB in size
The number of postcodes for selected areas, districts, sectors & zones were counted and the results appended to a data table. There are around 700 aggregated records created
This was done in 2 ways:
1. HAVING - data is grouped then filtered, counted & added to the data table one at a time
Code:
CurrentDb.Execute "INSERT INTO PostcodesCount ( TotalPostcodes, PostcodeArea, PostcodeDistrict, PostcodeSector, PostcodeZone )" & _
" SELECT Count(Postcodes.ID) AS TotalPostcodes, Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector, Postcodes.PostcodeZone" & _
" FROM Postcodes" & _
" GROUP BY Postcodes.InUse, Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector, Postcodes.PostcodeZone," & _
" Right([PostcodeDistrict],1), Right([PostcodeSector],1), Right([PostcodeZone],1)" & _
" HAVING (((Postcodes.InUse)=True)" & _
" AND ((Postcodes.PostcodeArea) Like 'B*' Or (Postcodes.PostcodeArea) Like 'C*' Or (Postcodes.PostcodeArea) Like 'H*' Or (Postcodes.PostcodeArea) Like '*L')" & _
" AND ((Right([PostcodeDistrict],1))='0' Or (Right([PostcodeDistrict],1))='3' Or (Right([PostcodeDistrict],1))='5' Or (Right([PostcodeDistrict],1))='8')" & _
" AND ((Right([PostcodeSector],1))='1' Or (Right([PostcodeSector],1))='2' Or (Right([PostcodeSector],1))='5' Or (Right([PostcodeSector],1))='8')" & _
" AND ((Right([PostcodeZone],1))='A' Or (Right([PostcodeZone],1))='N' Or (Right([PostcodeZone],1))='Q' Or (Right([PostcodeZone],1))='X'));"2. WHERE - data is filtered then grouped, counted & added one at a time
Code:
CurrentDb.Execute "INSERT INTO PostcodesCount ( TotalPostcodes, PostcodeArea, PostcodeDistrict, PostcodeSector, PostcodeZone )" & _
" SELECT Count(Postcodes.ID) AS TotalPostcodes, Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector, Postcodes.PostcodeZone" & _
" FROM Postcodes" & _
" WHERE (((Postcodes.InUse)=True)" & _
" AND ((Postcodes.PostcodeArea) Like 'B*' Or (Postcodes.PostcodeArea) Like 'C*' Or (Postcodes.PostcodeArea) Like 'H*' Or (Postcodes.PostcodeArea) Like '*L')" & _
" AND ((Right([PostcodeDistrict],1))='0' Or (Right([PostcodeDistrict],1))='3' Or (Right([PostcodeDistrict],1))='5' Or (Right([PostcodeDistrict],1))='8')" & _
" AND ((Right([PostcodeSector],1))='1' Or (Right([PostcodeSector],1))='2' Or (Right([PostcodeSector],1))='5' Or (Right([PostcodeSector],1))='8')" & _
" AND ((Right([PostcodeZone],1))='A' Or (Right([PostcodeZone],1))='N' Or (Right([PostcodeZone],1))='Q' Or (Right([PostcodeZone],1))='X'))" & _
" GROUP BY Postcodes.InUse, Postcodes.PostcodeArea, Postcodes.PostcodeDistrict, Postcodes.PostcodeSector, Postcodes.PostcodeZone," & _
" Right([PostcodeDistrict],1), Right([PostcodeSector],1), Right([PostcodeZone],1);"The tests were each run 10 times and the average calculated for each test
Unexpectedly using HAVING was slightly faster but the difference in times was negligible
b) Patients
I then decided to try again adapting the dataset from my recent patient login kiosk mode example.
I imported the same 3300 records 9 times over to give a dataset of around 30000 records.
Duplicating patient names and dates of birth doesn’t matter for these tests.
Each record includes gender & date of birth (both indexed).
The database for this test is small enough to upload (attached)
Code was used to count the number of records grouping by birth day & birth month as well as gender and appended these record counts to another table.
The tests each created just over 700 records on each run.
As there were fewer records in this dataset, the code looped through each 3 times in each test
All tests were repeated 5 times and average values calculated
This time, there were 3 different tests:
1. HAVING - data is first grouped then filtered, counted and appended one at a time
Code:
For I = 1 To LC 'loop count
For M = 1 To 12 'month count
For D = 1 To 31 'day count
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS CountOfPatientID, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Month([DOB]), Day([DOB])" & _
" HAVING (((Month([DOB]))=" && M && ") AND ((Day([DOB]))=" && D && "));"
Next D
Next M
Next I2. WHERE – data is first filtered then grouped, counted and appended one at a time
Code:
For I = 1 To LC 'loop count
For M = 1 To 12 'month count
For D = 1 To 31 'day count
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS CountOfPatientID, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" WHERE (((Month([DOB]))=" && M && ") AND ((Day([DOB]))=" && D && "))" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Month([DOB]), Day([DOB]);"
Next D
Next M
Next I3. INSERT – data is grouped then all records were appended ‘at once’
Code:
For I = 1 To LC 'loop count
db.Execute "INSERT INTO tblData ( RecordCount, BirthDateMonth, Gender )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, Left([DOB],5) AS BirthDateMonth, tblPatients.Gender" & _
" FROM tblPatients" & _
" GROUP BY Left([DOB],5), tblPatients.Gender, Day([DOB]), Month([DOB])" & _
" ORDER BY tblPatients.Gender, Left([DOB],5);"
Next IResults were as follows
In these tests WHERE was faster than HAVING but the difference between them was once again negligible.
INSERT is of course dramatically faster than either of the other 2 methods as it all happens ‘at once’ rather than 'row by agonising row' (RBAR) in a recordset loop
=======================================================
Incidentally, I ran 4 different versions of the HAVING tests to compare the relative efficiency of each
All gave EXACTLY the same results but the times were VERY different
The comparative speeds were this time what I had expected
Method 1 (as above) - using Month & Day functions - approx. 78s for 3 loops
Code:
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Month([DOB]), Day([DOB])" & _
" HAVING (((Month([DOB]))=" & M & ") AND ((Day([DOB]))=" & D & "));"Method 2 - as method 1 but also formatting dates by mm/dd/yyyy - approx. 298s for 3 loops
Code:
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Month(Format([DOB],'mm/dd/yyyy')), Day(Format([DOB],'mm/dd/yyyy'))" & _
" HAVING (((Month(Format([DOB],'mm/dd/yyyy')))=" & M & ") AND ((Day(Format([DOB],'mm/dd/yyyy')))=" & D & "));"Method 3 - using Left & Mid functions - approx. 170s for 3 loops
Code:
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), Mid([DOB],4,2), Left([DOB],2)" & _
" HAVING ((Int(Mid([DOB],4,2))=" & M & ") AND (Int(Left([DOB],2))=" & D & "));"Method 4 – using Date Part functions – approx. 160s for 3 loops
Code:
db.Execute "INSERT INTO tblData ( RecordCount, Gender, BirthDateMonth )" & _
" SELECT Count(tblPatients.PatientID) AS RecordCount, tblPatients.Gender, Left([DOB],5) AS BirthDateMonth" & _
" FROM tblPatients" & _
" GROUP BY tblPatients.Gender, Left([DOB],5), DatePart('m',[DOB]), DatePart('d',[DOB])" & _
" HAVING ((DatePart('m',[DOB])=" & M & ") AND (DatePart('d',[DOB])=" & D & "));"========================================================
Overall Conclusions
The HAVING vs WHERE tests were done to provide evidence that the use of HAVING is far less efficient than using WHERE.
Logically this MUST be the case
However, the tests haven’t worked out anything like I had expected.
Now it may be that my code is flawed or my datasets not sufficiently large to make the relative efficiency of each test create significant differences.
:banghead:
OR I've just managed to show that this commonly expressed viewpoint is actually not true or has minimal effect.
I would appreciate others running the same tests and providing feedback on the results obtained.
I would also appreciate comments on the tests themselves together with any suggested improvements or alterations to the process.
Attachments
Last edited:

")

")
 I adopted it very long ago when I saw a performance improvement in a query I changed.
I adopted it very long ago when I saw a performance improvement in a query I changed.