Jacek
I wrote this a couple of hours ago but the site went down for a while ....
Thankfully I had saved it as a text file before trying to post it!
I have severe doubts that the cartesian join approach will work reliably but feel free to attempt it.
If I was going to do this myself (but I'm not ...UNLESS you pay me a lot of money), I would definitely use TEMP tables & make lots of backups at every step of the process
When I've had to do anything at all similar its usually been to clear up a mess created by someone synchronising data badly.
Particular problems always come where :
a) the import source table has no PK or the PK values do not match those in the destination table
AND
b) there are null values in one or more fields in one or both tables being compared
In such cases the dataset ended up with lots of duplicates and/or deleted multiple records that should have been retained
See the second part of my
Synchronising Data article for more details on this
In such cases, fixing the problems consisted of multiple steps including (not necessarily in this order)
a) restoring missing records from old backups
b) identifying duplicate values in the source table and eliminating those
c) identifying duplicate values in the destination table and eliminating those
d) performing append,update & delete on the correct records left over after the above
Doing all this needs great care and each step needs to be checked
When I've done this for clients, the invoice has been substantial as it can take many hours
Doing it as a one-off is bad enough and should always be followed by a redesign of the data structure to prevent recurrence. Otherwise, you will need to do this repeatedly - probably EVERY time you import new data
The fact that you have been asking about this through several threads over several weeks indicates that the data structure you have is very wrong.
Now my suggestion is to go back a few stages and reconsider the fields needed to ensure uniqueness then make a composite index on those (setting the index to No Duplicates).
As you know, no more than 10 fields can be used in a single index but I would be incredulous if you need anything like 10. As previously stated 5 fields is the most I've ever needed in an index and , with hindsight, even that was due to poor design.
To illustrate why I keep stressing this, lets consider a table with 5 fields.
For simplicity, lets assume each field has 10 allowed values
That gives a possible 10 to the power 5 (10E5) unique combinations of records
If you have 10 fields each with 100 allowed values then there could be 100E10 different records
Multiply up in the same way for your tables with even more fields as shown in post #1
Of course many fields will have no restriction on the allowed values so in theory there could be an infinite number of possible records with no duplicates.
If you index fields appropriately with no duplicates allowed, then the process of synchronising data will become RELATIVELY trivial.
So I would look at your existing data carefully &, by careful experimentation, identify which COMBINATION of fields NEVER give duplicate values - use the built in Duplicates Query wizard to help with this.
EITHER start with two fields and keep adding one field at a time (in different orders) until duplication stops
OR start with all fields and remove one field at a time (in different orders) until duplication begins.
Will it be tedious - YES
Will it take a long time - YES ...unless you can see patterns to speed up the process
When you've got the answer set up the UNIQUE index
Now go back to the original tables & create a SELECT query with Inner joins on just those fields. Check the dataset of matching records.
If its OK (with no duplicates) then convert to outer joins to identify unmatched records.
If still OK, convert to append or delete as appropriate.
One final thing in this extended essay.
Null values will complicate matters. A null value is not the same as anything else ...not even another null
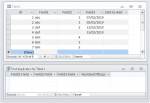
For example look at the following table which contains several nulls
To us, it is 'obvious' that records 6 & 7 are duplicates but because both have NULL dates, Access says there are no duplicates.
Now imagine the same issue when synchronising data on 20 or so fields containing null data
As it says in the article, my work-round is to temporarily convert nulls in both tables to unlikely values e.g. 01/01/9999 for dates, -1000000 for numbers and a character string such as |¬#~¬`| for text.
Then do your synchronisation and afterwards restore those values back to null
I hope somewhere in this lengthy answer, you will find the solution to your problem.
")