fat controller
Slightly round the bend..
- Local time
- Today, 00:34
- Joined
- Apr 14, 2011
- Messages
- 758
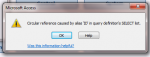
I am trying to get a combo box to only show unique values, but I can't get it to work properly - it still shows duplicates in the list.
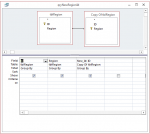
The Row Source is set to
SELECT DISTINCT Areas.ID, Areas.Area FROM Areas ORDER BY Areas.Area;
And the combo is bound to column 2
Anyone able to give me a nudge in the right direction please?
The Row Source is set to
SELECT DISTINCT Areas.ID, Areas.Area FROM Areas ORDER BY Areas.Area;
And the combo is bound to column 2
Anyone able to give me a nudge in the right direction please?
")